

В этой статье речь пойдет о цифрах, которые имеют значение: о надежности, валидности и других ключевых составляющих эффективности современных инструментов оценки.
***
Выбор инструментов оценки и измерение эффективности их применения вызывают у профессионалов сферы HR немало вопросов. В современном бизнесе под рукой у HR есть огромное количество данных, но даже они зачастую не позволяют однозначно сказать, в какой мере тот или иной инструмент подходит для решения конкретной HR-задачи и позволяет ее решить. Как это часто бывает, важны не только сами цифры, но и окружающий их контекст. На что стоит опираться, определяя контуры системы оценки и формируя процессы тестирования? Как извлечь максимальную пользу от применения инструментов оценки?
Разработчики компании «Бизнес Психологи» много лет искали ответы на эти вопросы, анализируя свой опыт и результаты проведения самых разных HR-проектов: от оценки кандидатов до измерения вовлеченности сотрудников, от диагностики команд до анализа продуктивности и эффективности деятельности подразделений и компаний в целом. Накопленный опыт позволил разложить процесс измерения качества и пользы от тестирования на отдельные компоненты — удобные в описании и практичные в применении. В этой статье речь пойдет о том, как обычно оценивается прямой эффект от применения инструментов оценки, почему этого может быть недостаточно, а также об измерении ключевых характеристик любого инструмента оценки — его надежности и валидности.
Время и деньги
При определении качества инструментов оценки, прежде всего, необходимо разобраться, что имеется в виду под выгодой (то есть пользой) от их применения. Одна из самых очевидных точек старта для такого анализа — это оценка временных и материальных затрат в различных сценариях. Например, в компании существует воронка отбора, на одном из этапов которой перед HR стоит задача: отобрать из 1000 кандидатов 100 финалистов.
«Можно провести 1000 интервью, а можно упростить процесс отбора, отсеяв какую-то часть людей с помощью тестирования», — говорит Максим Пескин, менеджер по разработке новых продуктов компании «Бизнес Психологи».
По оценкам экспертов, отсев примерно 600−700 кандидатов по итогам 1000 тестирований будет вполне реалистичным результатом. Задача, таким образом, сводится к тому, чтобы сравнить необходимые вложения времени и денег.

Проведение 1000 интервью — это громадные временные затраты. Если одно интервью занимает в среднем час, то в действительности HR может понадобиться около 2000 часов: необходимо учесть подготовку к интервью, обработку результатов, их коммуникацию и принятие решений — и это в предположении, что критерии (то есть, к примеру, модель компетенций) четко определены, понятны всем участникам процесса и отражают действительно значимые требования.
Безусловно, само внедрение тестов также создает как временные, так и материальные затраты: необходимо наладить систему оценки, научиться пользоваться тестами как инструментом и т. д. Однако затраты времени на проведение интервью заметно снижаются, ведь значительная часть кандидатов отсеивается, не доходя до этого этапа.
«Выгода в прямом смысле начинается тогда, когда вариант с тестированием оказывается дешевле подхода, в котором проводится только интервью, — как в смысле материальных, так и временных затрат», — объясняет Максим.
При этом имеют значение и объем потока кандидатов, и форма воронки отбора: чем больше людей у HR «на входе», тем выгоднее автоматизировать процесс оценки, и чем сильнее сужается воронка (другими словами, чем более жесткий требуется отсев), тем выгоднее проводить тестирование. Вместе с тем выигрыш во времени может иметь гораздо большее значение для бизнеса, чем экономия денег. Речь идет не просто о том, что в одном сценарии HR необходимо потратить 2000 часов, а в другом — всего лишь 600. Выигранное время можно перенаправить на задачи, которые приносят гораздо большую отдачу, — т. е. стратегические, системные, долгосрочные проекты, требующие экспертизы и погружения. Важность таких задач в практике HR постоянно возрастает (более подробно этот вопрос обсуждается в нашем исследовании «HR на острие изменений: тенденции и практики управления персоналом» ССЫЛКА).
Форма и содержание
Сравнение разных подходов и методов оценки с точки зрения временных и материальных вложений — это важно, однако такой взгляд в общем-то игнорирует вопрос содержания тестов и их влияния на качество найма.
«Необходимо понимать, корректно ли произведен отсев кандидатов, не „потеряла“ ли компания из-за проведенного тестирования самых ценных людей. И наоборот: получилось ли „поймать“ более подходящих людей, так чтобы интервью могло приносить еще большую пользу, позволяя отобрать самых ценных претендентов», — обращает внимание Максим Пескин.
Положительная динамика в качестве найма наблюдается в том случае, когда с помощью теста удается более четко сфокусироваться на критически важных аспектах и качествах кандидатов, прежде «выпадавших» из зоны внимания. Таким образом, вопрос эффективности теста как фильтра выводит на первый план не только экономию времени и бюджета, но и «ценность» потока кандидатов для организации, их потенциальное долгосрочное влияние на деятельность и показатели бизнеса.
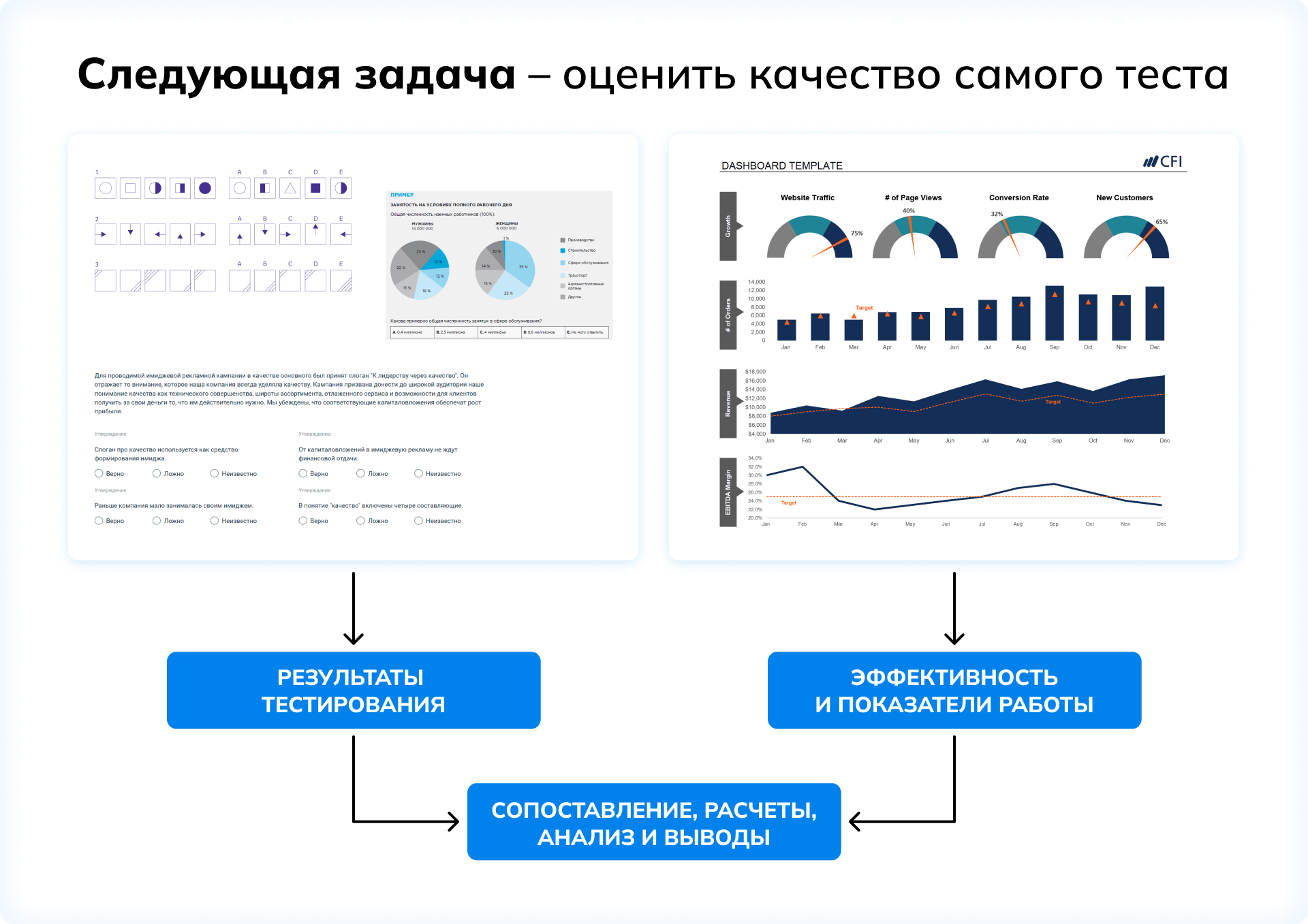
Следующий логический шаг вполне очевиден. Чтобы определить качество теста, необходимо сопоставить данные, полученные по результатам тестирования, с показателями эффективности рабочей деятельности сотрудников. Важно, чтобы используемый инструмент точно и достоверно предсказывал то, что приносит полезный, ощутимый и измеримый результат в реальной жизни.
«Это универсальная схема проверки инструментов оценки, от которой никуда не деться. При этом каждый из компонентов этой схемы — то есть и результаты тестирования, и показатели эффективности, и объединяющий и сопоставляющий их анализ, — имеет свои особенности и заслуживает детального рассмотрения», — уточняет Максим Пескин.
Базовые составляющие эффективности
Если на базовом уровне достаточно уметь интерпретировать результаты тестирования, то продвинутый пользователь психометрических инструментов, безусловно, должен уметь оценивать надежность и валидность применяемых методик. И если вовремя распознать, что с тестом «что-то не так» с точки зрения этих ключевых параметров, все остальные аналитические задачи, отталкивающиеся от результатов прохождения такого теста, в принципе теряют актуальность.

Надежность и валидность проще всего изобразить и представить себе с помощью простой метафоры: стрельбы по мишени. Необходимо отметить, что эта метафора не несет в себе ни точных аналогий, ни глубокого символизма: она лишь позволяет начать разговор на обозначенную тему (хотя надежность и валидность — по сути универсальные категории, появляющиеся в рамках любых задач измерения, так что эта метафора отнюдь не единственная).
Если произведенные выстрелы попадают в разные области мишени, это говорит о том, что результат на фундаментальном уровне не постоянен и не предсказуем. Именно постоянство (или устойчивость) результатов — в частности, результатов оценки или измерения — специалисты обозначают термином «надежность».

«Определение надежности инструмента первично: до тех пор, пока нет устойчивости, никакие дальнейшие оценки, измерения и аналитика просто не имеют ценности», — говорит Максим Пескин.
Итак, надежность «появляется» в этой метафорической картине тогда, когда условные выстрелы начинают попадать в одну и ту же область мишени. На этом этапе возникает новый вопрос — о том, куда именно удается так устойчиво, повторяемо стрелять. Очевидно, чем ближе выстрелы ложатся к «десятке», тем ближе процесс к тому, что требовалось. В частности, применительно к процессу оценки персонала речь идет о том, насколько результаты этой оценки оказываются близки к реальности, а инструмент — к корректному исполнению поставленной задачи измерения. Это и обозначается термином «валидность».
Оценка надежности
Основной смысл надежности инструмента — это повторяемость результатов оценки. Но как именно ее измерить? Российский и международные стандарты тестирования описывают ряд подходов к измерению надежности и связанных с ними требований. Одним из самых методологически простых вариантов является так называемая ретестовая надежность. Чтобы ее измерить, группа людей проходит оценку определенным инструментом, а спустя некоторое время эти же участники заново проходят тот же самый инструмент, после чего аналитики ищут корреляцию между результатами. Несколько более сложен подход к оценке надежности с помощью альтернативных или параллельных форм, который предполагает разделение теста на несколько эквивалентных частей (в зависимости от размера банка заданий разработчик может, например, дать одной группе только четные задания, а другой только нечетные, или же сделать «искаженную версию» теста, в которой сохраняется логическая структура заданий, но меняется их содержательное наполнение).
«Однако сегодня в реальности надежность чаще всего измеряют не столько с точки зрения устойчивости результатов во времени, сколько через единство и постоянство логического содержания самих заданий, то есть как внутреннюю согласованность инструмента», — рассказывает Максим Пескин.
Такой подход фокусируется на вопросе о том, работает ли набор заданий инструмента как единое целое, направлены ли они на измерение той же характеристики. Безусловно, в идеальном случае результат должен оставаться устойчивым не только с течением времени, но и под влиянием разного рода случайных факторов (например, случайностей выдачи заданий или тактики прохождения теста участником).
Первичность ошибки
При этом обеспечить абсолютно устойчивые результаты тестирования физически невозможно: определенная ошибка измерения будет присутствовать всегда, поэтому все методологии тестирования предусматривают наличие ошибки измерения и показывают ее связь с надежностью. Однако если в классической теории тестирования надежность считается первичной характеристикой теста, а ошибка измерения может быть рассчитана, то в IRT первично именно значение ошибки измерения, а надежность является производной от нее. Строго говоря, в IRT первична так называемая информационная функция заданий: каждое задание теста сообщает нам определенную информацию, снижая тем самым уровень неопределенности.
«Значение ошибки измерения связано именно с количеством информации. Оно должно увеличиваться по мере того, как респондент получает следующие задания; если этого не происходит, если новые задания не снижают неопределенность, значит, тест по существу завершен», — объясняет Максим Пескин.
Считается, что все подходы к измерению надежности по большому счету эквивалентны. Однако для более точной интерпретации и принятия решений бывает важно уточнить, как именно определялась надежность данного инструмента (и, соответственно, какую ошибку измерения придется учитывать при его применении).
Оценка валидности
Говоря о надежности инструмента, специалисты сосредотачивают внимание на снижении случайных ошибок. При оценке валидности речь идет об отсутствии или минимизации систематических погрешностей — т. е. о том, что результаты должны быть не только однозначными и устойчивыми, но и правильными, осмысленными, ценными.

Очевидная и содержательная валидность
Говоря о валидности, специалисты чаще всего выделяют 4 основных категории: они упоминают очевидную, содержательную, конструктную и критериальную валидность. Стоит отметить, что можно встретить и другие термины; остается открытым и общий спор о том, чем именно являются эти категории: подходами к оценке валидности, компонентами, типами или еще чем-то (и, как все споры, представляющиеся в первую очередь терминологическими, этот по существу является вполне философским; впрочем, вопросы эпистемологии выходят за рамки настоящей статьи).
Первые два компонента валидности определяются посредством сбора мнений экспертов.
«Очевидная валидность связана с внешней убедительностью инструмента: тест должен выглядеть как тест, в котором, например, правильный ответ не должен очевидно выделяться своей детализацией и проработанностью, по сравнению с неправильными», — объясняет Максим Пескин.
Если же речь заходит о валидности опросников, то сегодня инструменты с механизмом вынужденного выбора (т.е. ипсативные) будут почти наверняка более очевидно валидными, чем те, в которых такого механизма нет.
«Обмануть ипсатив сложнее, а сделать это незаметно — практически невозможно», — уточняет Максим.
Таким образом, очевидная валидность указывает на отсутствие явных проблем в дизайне инструмента и отвечает на вопрос: «Похоже ли, что этот тест (или опросник) хоть как-то будет работать?»

Показатель содержательной валидности инструмента часто воспринимается пользователями (а нередко и специалистами-разработчиками) в очень узком смысле — как мера прямого содержательного соответствия инструмента рабочим задачам. Например, в случае тестов встречается буквально такой критерий выбора, как «похожи ли тексты/таблицы в тесте на те, с которым сотрудники на данной должности работают в действительности». Однако такой подход представляется не вполне корректным — по меньшей мере, недостаточным.
Во-первых, не менее важной стороной содержательной валидности (недаром ее иногда называют логической валидностью) является корректность операционализации, то есть правильность и полнота отражения в заданиях исходного теоретического конструкта, соответствующего целевым оцениваемым характеристикам.
Другими словами, для того, чтобы инструмент считался содержательно валидным, необходимо сперва убедиться в том, что выбранный конструкт раскрыт в нем в полной мере. К примеру, для числового теста — если конструкт состоит в анализе разнообразных числовых данных — важно убедиться в том, что задания требуют проведения разных вычислений (а не фокусируются на узком круге формул), работы с разными видами представления информации и т. п.
Во-вторых, идея соответствия инструмента рабочим задачам не так прямолинейна. Естественно, можно сделать тест, который будет напрямую повторять рабочие задачи для какой-то должности — но, вероятнее всего, он будет оценивать не столько способность, сколько специфический комплекс из навыка и опыта, и результаты такого тестирования не помогут прогнозировать эффективность для других должностей и рабочих задач. Поэтому гораздо более практичный подход состоит в том, что задания должны отражать не содержание рабочих задач, а процесс их решения: для того, чтобы успешно выполнить задания теста, необходимо совершить ту же последовательность логических операций, которая требуется в повседневных рабочих задачах.
«В голове у успешного кандидата должны „крутиться те же шестеренки“. А для этого нужно, чтобы та же последовательность логических шагов, те же умозаключения, которые заложены в тесте, были нужны и в реальных рабочих задачах», — говорит Максим Пескин.
Нередко для этого приходится довольно существенно отойти от «контента» привычных рабочих задач — чтобы обнажить именно интеллектуальную или личностную компоненту, собственно требующую психометрической оценки.
Конструктная и критериальная валидность
Два других аспекта валидности оцениваются уже с помощью экспериментальных данных.
Конструктная валидность — это, как следует из названия, количественная оценка соответствия шкалы инструмента заявленному конструкту (это уточнение особенно важно для опросников, содержащих множество шкал: этот показатель необходимо измерить для каждой). Золотым стандартом измерения конструктной валидности является подход MTMM (Multitrait-Multimethod). Этот подход предполагает, что необходимо проанализировать не только корреляции между оценками «того же» параметра другими инструментами (т.н. конвергентная валидность: оценки сходных характеристик, очевидно, должны быть близки), но и между оценками разных параметров разными инструментами (дивергентная валидность: оценки разных характеристик, напротив, не должны быть неожиданно близкими, ведь это заставило бы подозревать, что конструкт в исследуемом инструменте как минимум некорректно обозначен).
На практике, однако, ключевой является валидность по критерию, т. е. взаимосвязь результатов оценки с каким-то конкретным внешним параметром. Именно с этим типом валидности связана способность инструмента прогнозировать определенные аспекты производительности и эффективности работы сотрудника. При определении критериальной валидности спользуются три подхода, различающиеся по моменту сбора данных: в ретроспективных исследованиях результаты тестирования сопоставляются с прошлыми показателями работы, в конкуррентных (здесь нет опечатки: это слово означает не «соперничающий», а «одновременный») — с собранными за текущий период, а в предиктивных сбор рабочих показателей происходит в будущем, уже после завершения тестирования.
Для большинства аналитических задач все эти подходы можно считать эквивалентными и равноправными. Выбор между ними определяется единственно соображениями удобства, и собранные данные в любом случае говорят о прогностической силе инструмента. Однако в тех случаях, когда необходимо оценить влияние вовлеченности, например, на лояльность сотрудника, готовность прикладывать дополнительные усилия или, напротив, покинуть компанию, более корректным будет именно предиктивный подход, который поможет понять, что будет происходить с участниками в перспективе.
Валидность и качество найма
Чаще всего валидность оценивается через коэффициенты корреляции. Это удобный показатель, но у него нет, собственно говоря, физического смысла: это не доля успешно нанятых сотрудников, не процент верных кадровых решений, не отдача от инвестиций. Коэффициент корреляции лишь показывает, насколько близки к идеальной абстрактной прямой точки на диаграмме рассеяния.
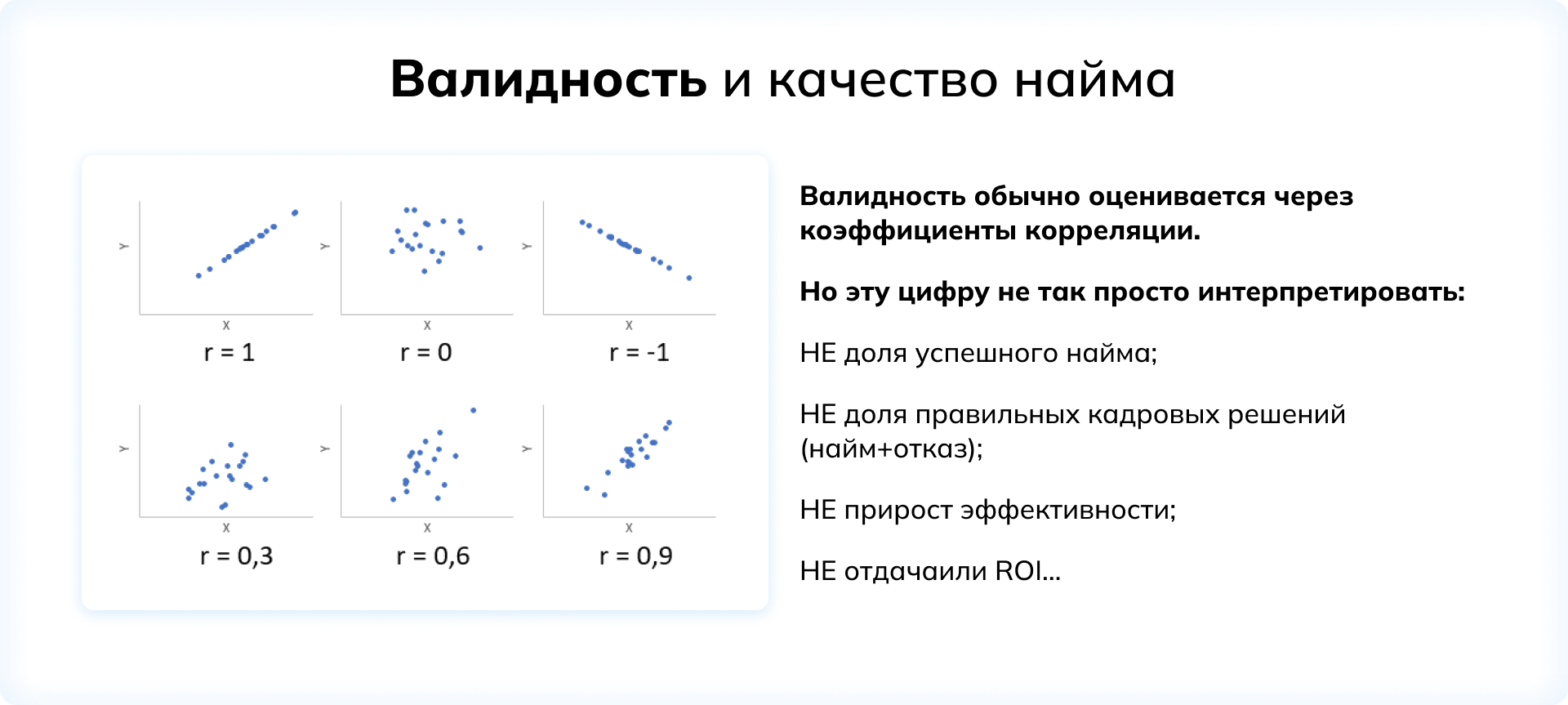
«Чтобы определить, что означает полученное значение коэффициента для бизнеса, его нужно рассмотреть в контексте нескольких других показателей», — объясняет Максим Пескин.
Лишь тогда можно будет судить о том, достаточно ли высок обнаруженный коэффициент корреляции -достаточно ли валиден и эффективен инструмент — и стоит ли его использовать в существующих обстоятельствах.
На вопрос о том, как коэффициент корреляции связан с качеством найма в реальности, отвечает широко известная теоретическая модель Тейлора-Рассела. Согласно этой модели, для определения качества найма (доли верных решений) необходимо учесть не только валидность теста, но и сложность выполняемой работы (в этой модели она выражена через долю сотрудников на данной должности, которые уже сейчас справляются со своей работой), а также форму воронки, т. е. жесткость отбора.
«Чем сложнее работа, тем больший эффект валидность инструмента оказывает на качество найма. И чем жестче отбор, тем большую роль играет валидность инструмента», — объясняет Максим Пескин.
Например, если известно, что с работой справляется 50% действующих сотрудников, и в то же время HR намерены дать положительный ответ практически любым кандидатам, то, независимо от применяемого инструмента, качество найма не поднимется существенно выше 50%. Если же конкурс составляет 10−20 человек на место, то, по мере внедрения все более валидных инструментов, можно увидеть неуклонный рост качества найма.
«Важно не просто иметь наготове валидный инструмент, но и применять его именно тогда, когда он может принести наибольшую пользу», — обращает внимание Максим.

Хотя сами термины «надежность» и «валидность» неразрывно связаны с темой оценки персонала, стоит учитывать, что они обозначают вполне универсальные понятия, возникающие в рамках любой задачи измерения. Корректность оценки всегда складывается из обоих параметров. Поэтому, говоря о качестве инструмента, во-первых, нужно понять, насколько повторяемо и устойчиво происходит измерение необходимой характеристики, удается ли свести к минимуму наличие случайных ошибок. А во-вторых, необходимо определить, насколько правильно это измерение, насколько оценка близка к действительным значениям и насколько устройство инструмента оценки (его конструкт и содержание) способствуют этому.
